
Hey there, we have just got into the year 2021. A new year comes with a new set of challenges. So, In this blog, we have handpicked quite a few NLP interview questions for 2021.
These questions are collected from professional interviewers of TOP MNC. Therefore, there is a high likelyhood that you may face these. Lets, get started!

What is tokenization?
It the process of splitting the sentences into individual words/tokens. Tokenization is very important because all the NLP operation can be possible if and only if the document/text has been converted into tokens
Example: Apple is expensive.
After tokenization, [‘apple’, ‘is’, ‘expensive’]
What is sentence tokenization?
If we want, we can also break the text into sentences rather than words. This is called sentence tokenization.
spaCy tokenizes the text and creates a Doc object. This Doc object uses our preprocessing pipeline’s components tagger, parser, and entity recognizer to break the text down into components. From this pipeline, we can extract any component, but here we’re going to access sentence tokens using the sentencizer component.
What is stopwords? how we can remove it using spacy?
Stopwords are those words that do not add much value to our text during text analysis but they are very much essential building sentences. example, of, is, a, etc.
Removal of stopwords eliminates noise and other distractions that may contribute to our model.
Spacy has its own stock of stopwords. The following shows how we can use spacy to remove stopwords.
What is stemming?
It is the process of reaching the root word. In stemming, we directly chop the trailing alphabets. As stemming does not follow any logic to reach the root word sometimes it fails to reach the root word.
Therefore, there is another way to reach the root word that is Lemmatization.
What is lemmatization and give one example?
Lemmatization takes into consideration the morphological analysis of the words. To do so, it is necessary to have detailed dictionaries that the algorithm can look through to link the form back to its lemma.
What is part of speech tagging? How it is done in Spacy
A sentence is build of words when put together in a systematic manner. Hence these words can be categories into groups, like a noun, subject, verb, adverb, etc.
The process of categorizing words in a sentence is called part of speech tagging.
import en_core_web_sm nlp = en_core_web_sm.load() # "nlp" Objectis used to create documents with linguistic annotations. docs = nlp(u"he went to school") for word in docs: print(word.text,word.pos_)
What is entity detection?
Entity detection is also known as entity recognition. It a more advanced form of language processing where words of a text are identified among certain elements like a geographical local, type of organization, people, country, automobile, etc.
Entity detection can quickly identify a text and the important topics that are frequently occurring.
For entity detection we shall use displacy of spacy library. Here is the example:
from spacy import displacy
print("entity detecton ------------->>>>>")
nytimes= nlp(u""" due to high polution in Delhi, people are forced to wear mask. In rencent year,
lungs realted disease has increases rapidly """)
entities=[(i, i.label_, i.label) for i in nytimes.ents]
print(entities)
What is dependency parsing?
It is a technique of extracting relations between the subjects of a sentence. Hence, It reveals which subject initiated the event. For example, Mr. Bill received the bill.
Here, Mr. Bill is the subject and it is the point of initiation of the event. on the contrary, “the bill” is at the receiving end of the event.
If dependency parsing is not done properly, we may end up thinking that “the bill received Mr.Bill”
It is quite complicated in nature, but the thankfully spacy library has in build algorithm to handle this kind of situation.
# Depency Parsing
docp = nlp (" Mr.Bill got the eletricity bill")
for chunk in docp.noun_chunks:
print(chunk.text, chunk.root.text, chunk.root.dep_,chunk.root.head.text)
What is word vectorization?
Whenever we think of any word, our mind unknowingly makes images, relates other words, and try to figure out what could be the upcoming text.
For example, if we come across the word “mango”, our brain renders the size, color, weight taste of mango. It tries to make sentences out of that word, like sweet mango juice or spicy mango pickle. But our brain will never try of making any sentence like “mongo has wheels, speed 50 miles per hour”.
At the same time, if our brain comes across the word “car”, then words like wheels, speed, horsepower, car insurance will pop up.
Now the biggest challenge is how a computer will relate a certain word with another relating word as our brain does? The answer is word vectorization.
In word vectorization, every word is described with a vector. The vector size is the same for all the words. But the value that expresses the words will be different.
Let’s have a look at how Spacy does it!
import en_core_web_sm nlp = en_core_web_sm.load() mango = nlp(u'car') print(mango.vector.shape) print(mango.vector)

What is the bag of words(BOW) model?
In nutshell, from a group of sentences, a vocabulary set is derived. In other words, a local dictionary consists of all unique words. The unique words become the features or columns.
Now all the sentences are represented in the form of zeros and ones wherever that word is present in the respective column. In other words, sentences are represented in vector format.
What isTF-IDF?
TF-IDF stands for term frequency-inverse document frequency. Primarily it is used to measure the importance of a term. It assigns more weight to the less occurring word.
There are situations where the occurrence of a term/word is very rare. On the other hand, some other words are appearing frequently.
For example, a document is about a “car”. Now “car” hardly appears 10 times in the document and that document is having more than 300 words in total. We have 100 such documents. How can we measure the importance of the word “car”?
TF: term frequency in a document
IDF: Inverse document frequency

What is the difference between RNN and LSTM?
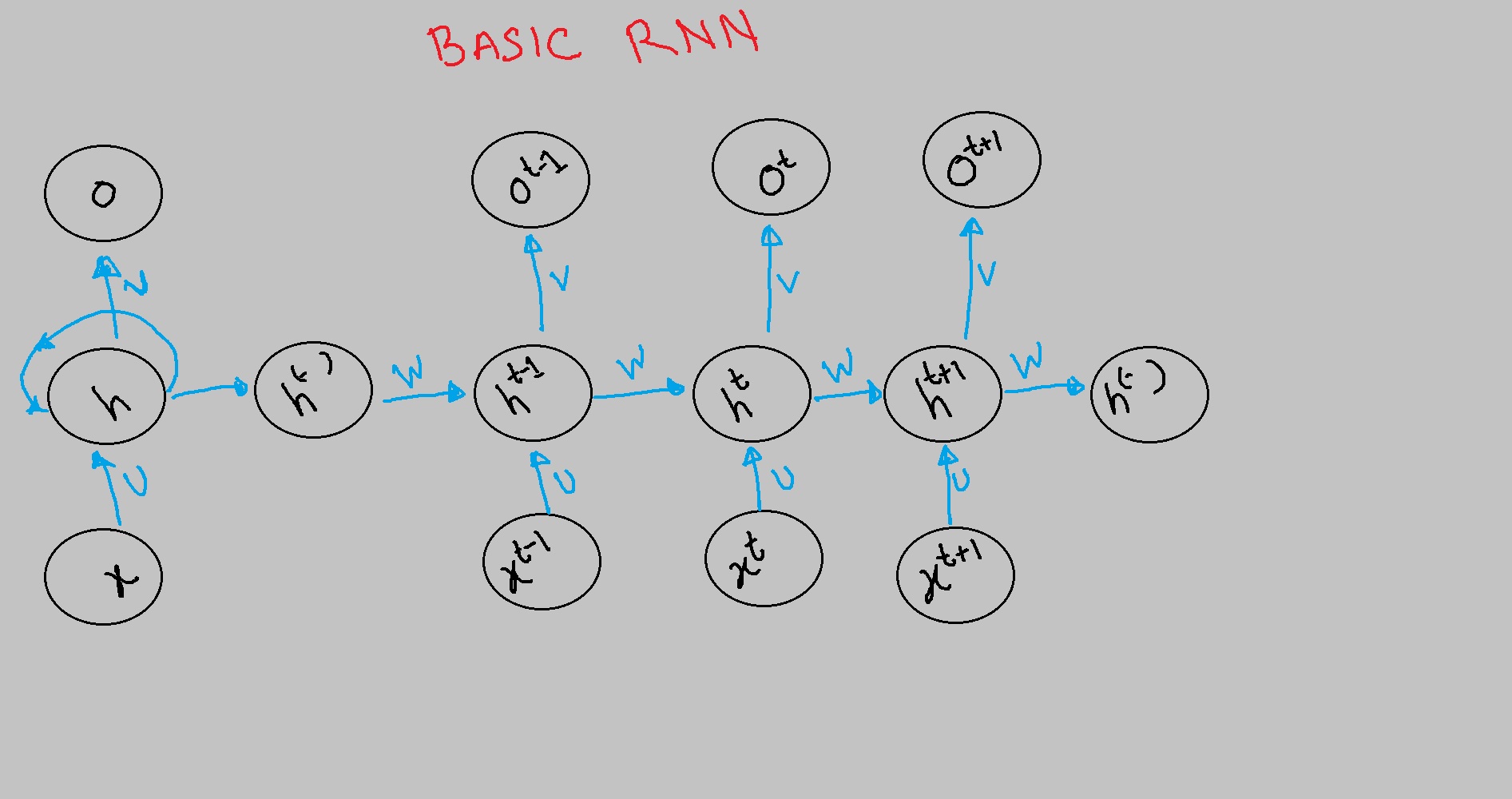
RNN is a kind of neural network in which the output of the network can go back to become an input to some neurons.

LSTM is also an RNN , has a special memory that decides the state of a certain variable based on the variable that is hold in memory.
We shall have detailed blog on LSTM
Conclusion:
In this blog, we discussed the top NLP interview questions for 2021. We shall keep updating this blog time and again for updated question in NLP.