

Introduction to AWS Glue Crawler :
Glue Crawler is a feature of AWS Glue which goes to one or more than one data source and extracts the metadata. It inspects the sources and generates the column name, types, size and other information. Hence, it got its name Crawler.
Click here for youtube tutorial.
Why AWS Glue Crawler is important :
Now a time being, just think that crawler is not there! Then we had to manually get into all the data sources and extract the column names, types and size etc. If a table is small, then its quite achievable but if a table has hundreds of columns then its not possible manually. Hence, we need crawler!
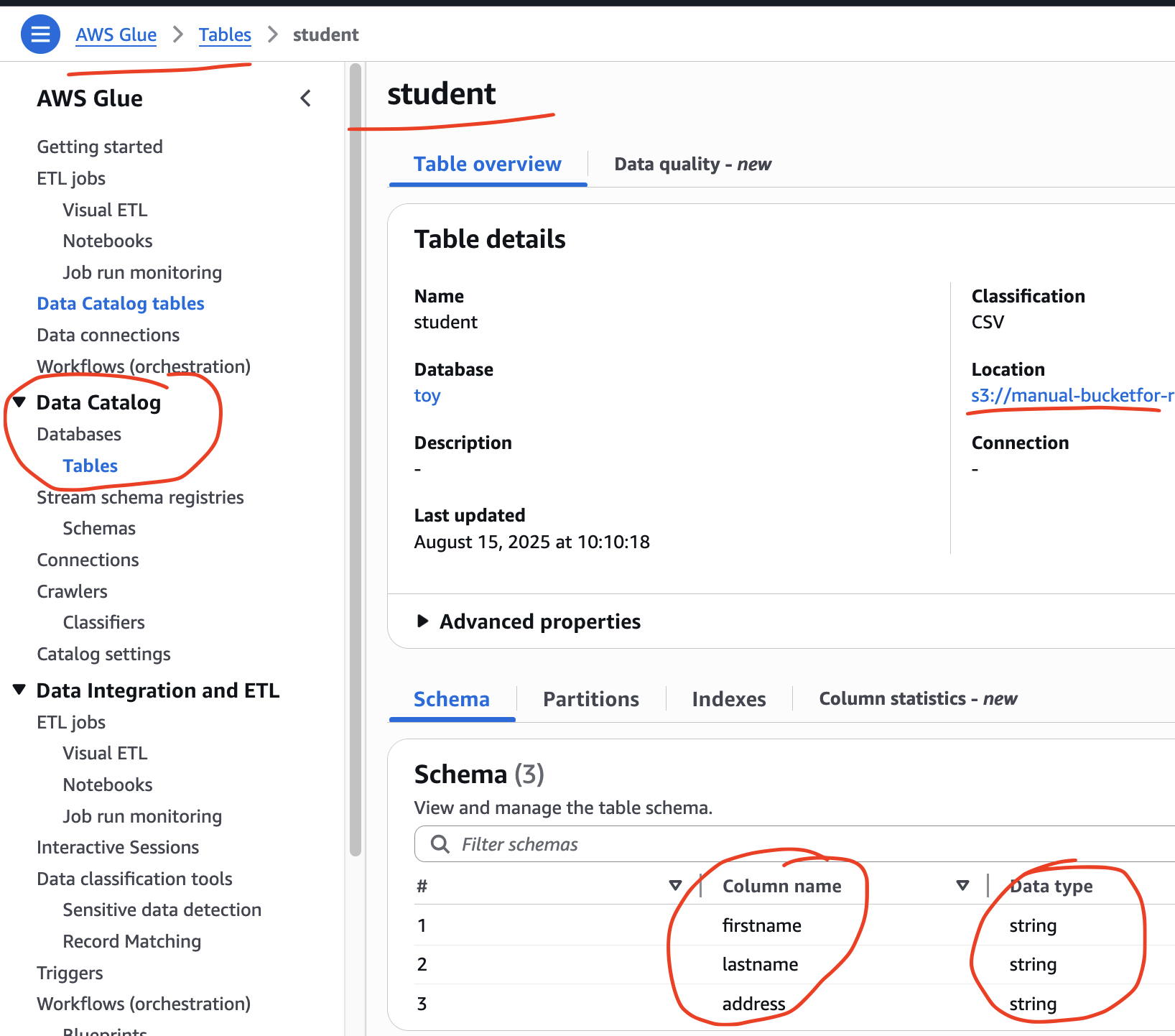
Crawler goes into specific data sources and creates metadata. In other words, this called as data catalog. Data catalog is a kind of a meta data store house. Once the data catalog is ready, we can build ETL job.
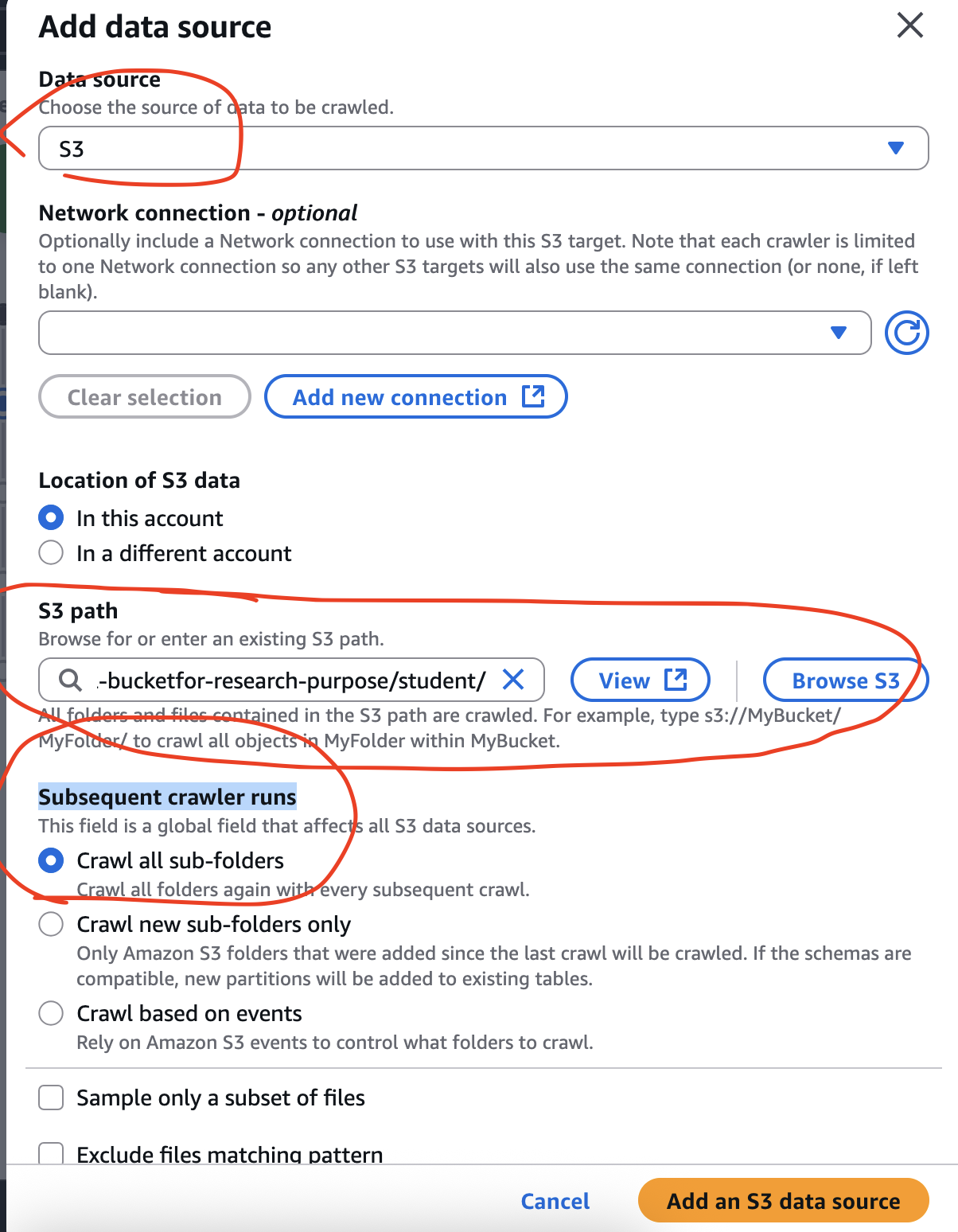
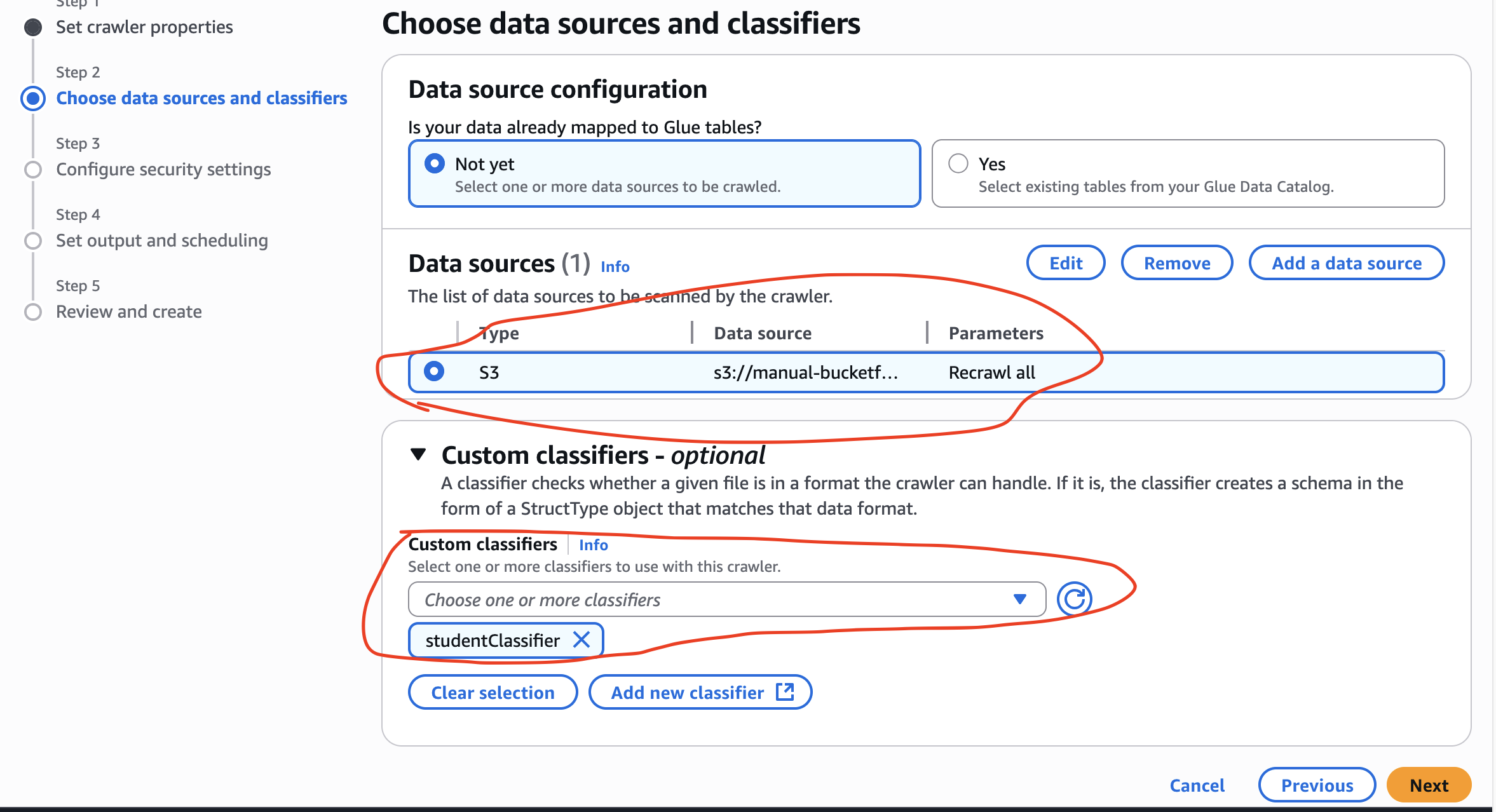
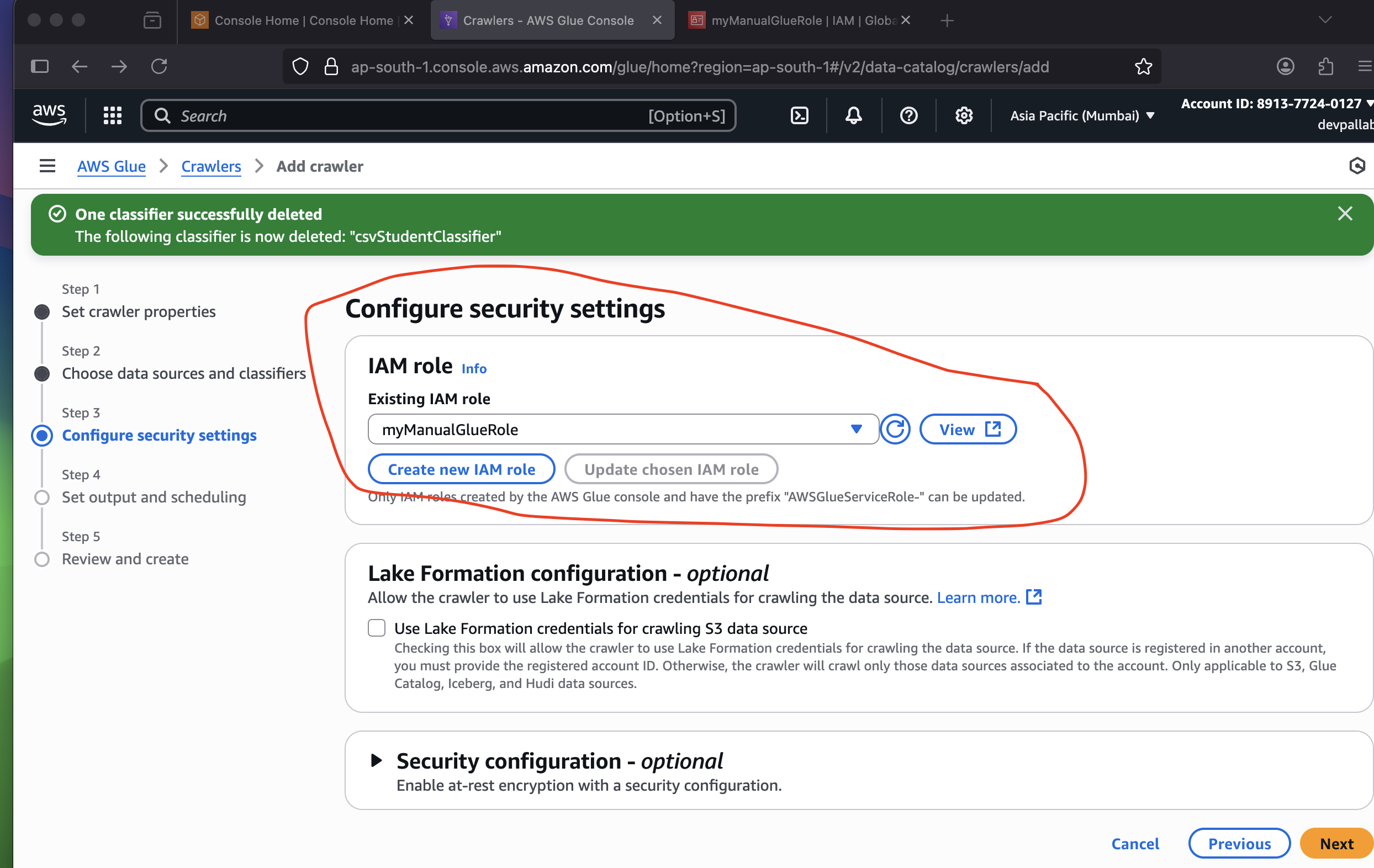
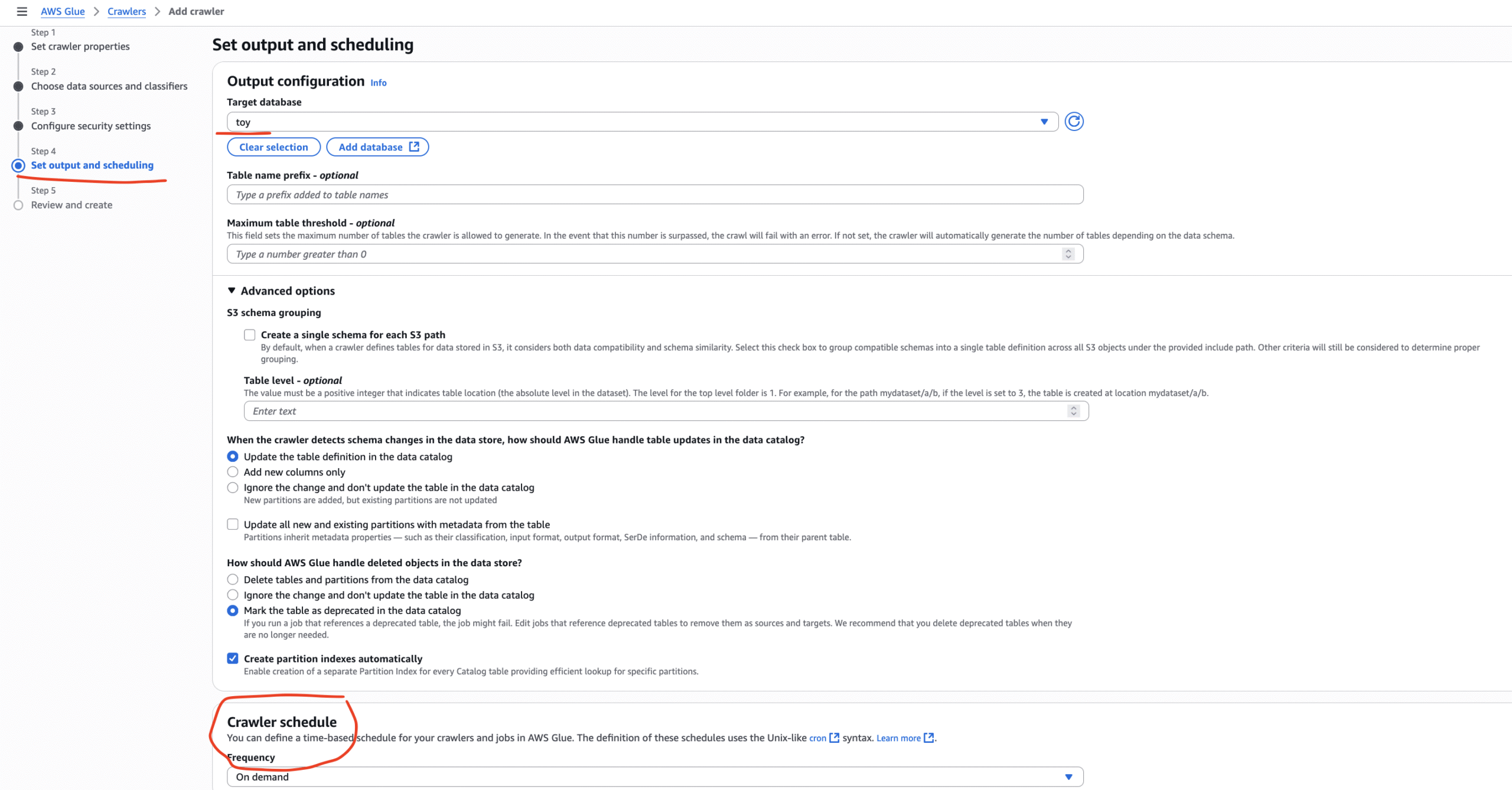
How to create crawler manually:
For this experiment, I have kept a csv file in a bucket. This csv file will be used by the Crawler to generate metadata. The csv data has three columns: firstname, lastname, address. Sample data shown below:
firstname,lastname,address Aarav,Sharma,"123 Green St, Mumbai" Aisha,Khan,"456 Blue Rd, Delhi" Rohan,Verma,"789 Red Ave, Bangalore" Sneha,Patel,"101 Yellow Ln, Hyderabad" Vikram,Gupta,"202 Orange Blvd, Chennai" Isha,Nair,"303 Pink St, Kolkata" Kabir,Mishra,"404 Purple Rd, Pune" Tanya,Aggarwal,"505 Brown Ave, Jaipur" Manish,Jain,"606 Silver Ln, Lucknow" Priya,Saxena,"707 Gold Blvd, Chandigarh"
Crawler Classifier :
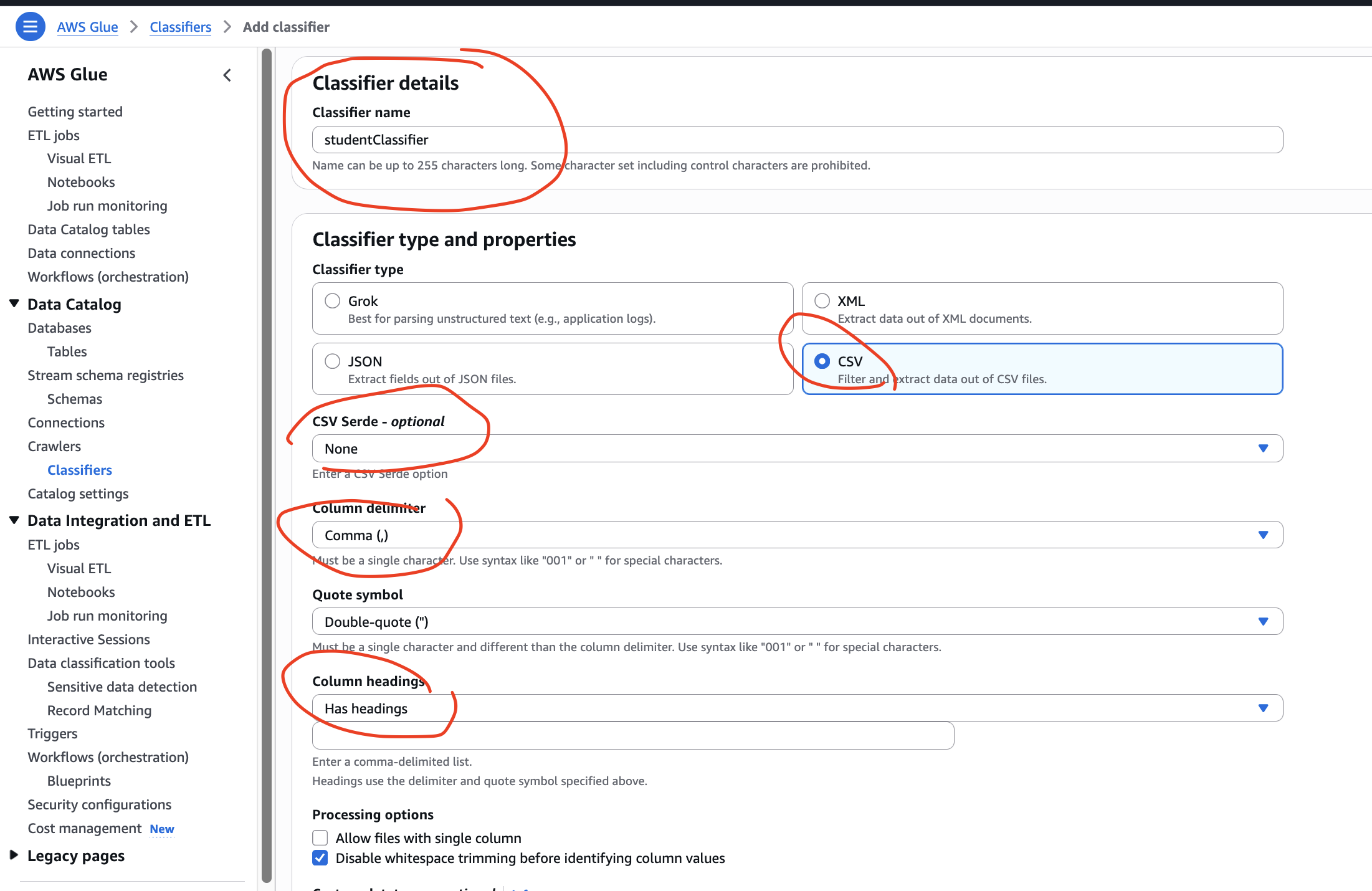
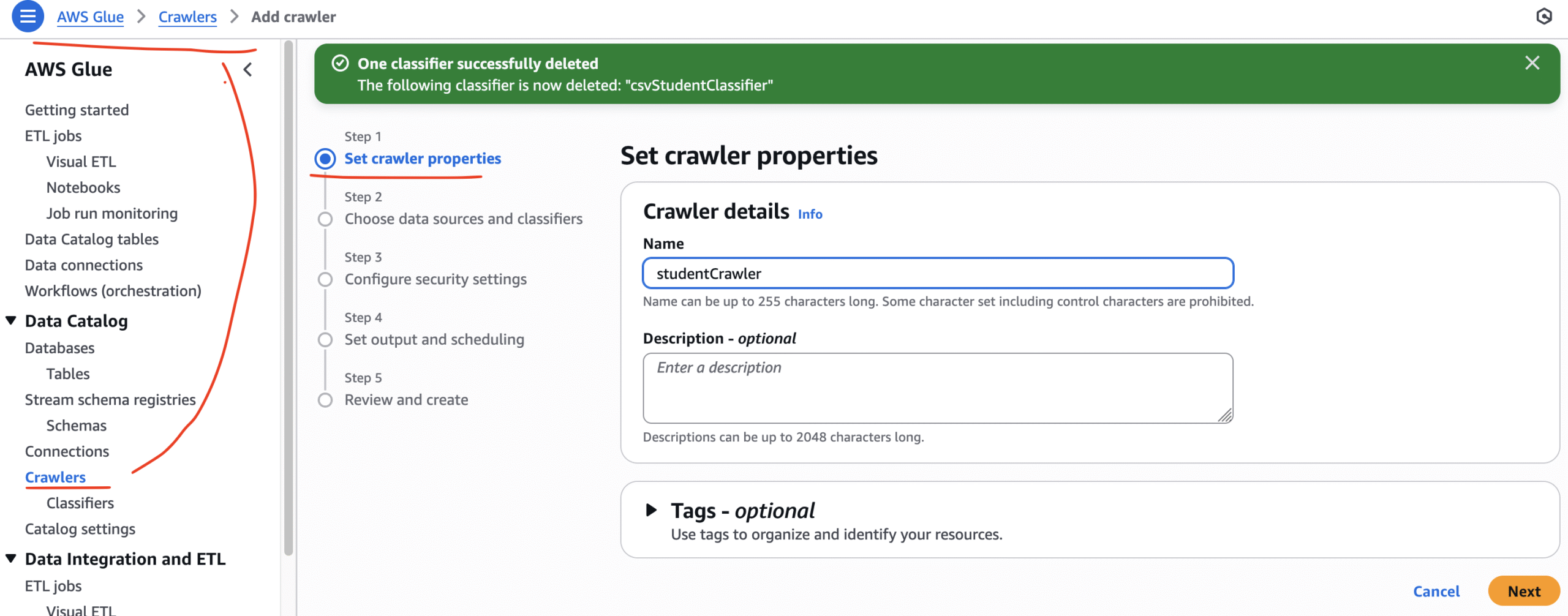
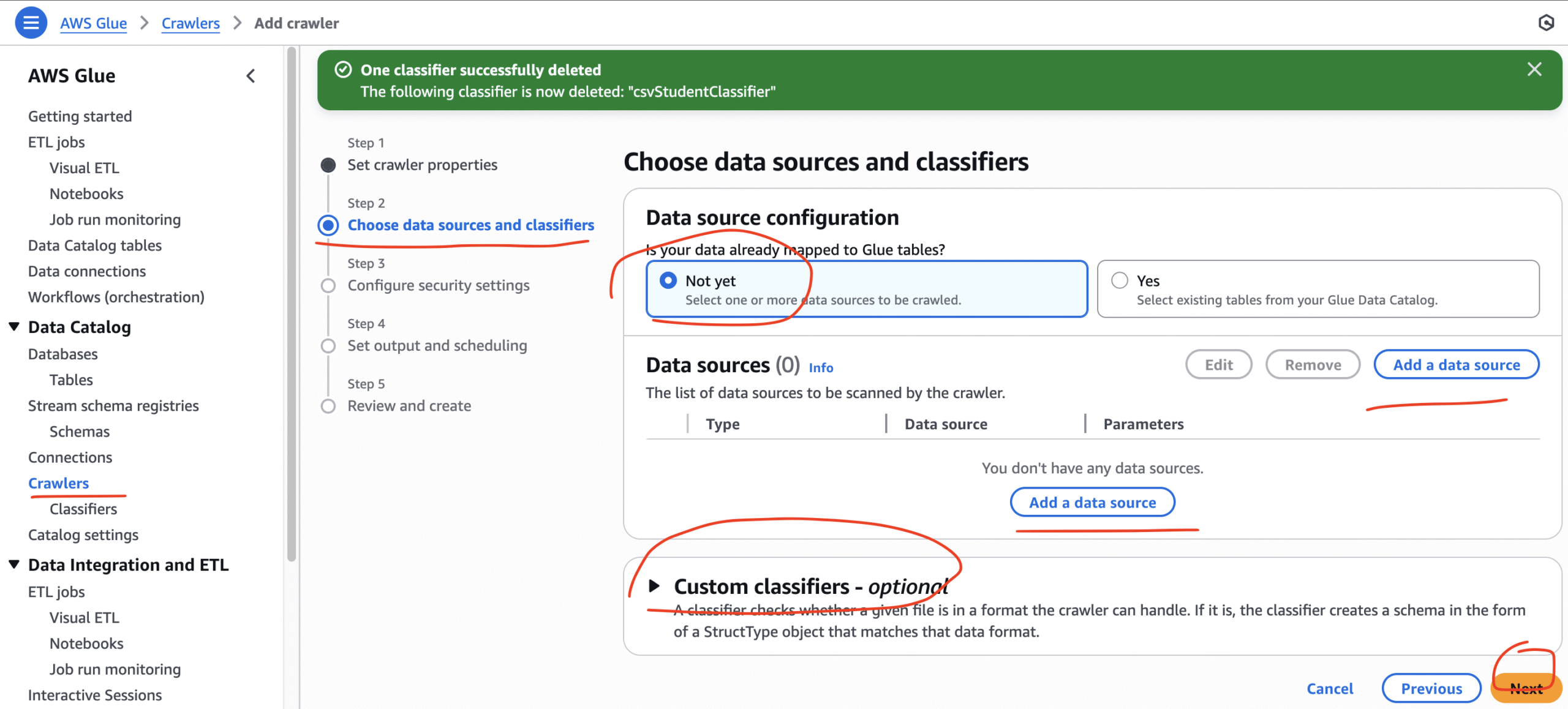
We nee to create a classifier with each crawler because only crawler without classifier, sometimes can’t differentiate between the data and the column names. Therefore, we need to create a classifier before we create a crawler!Now we shall move to Crawler page and build our configuration. We shall start with Classifiers.
Conclusion of Glue Crawler: