

Introduction of AWS GLUE :
Hello Readers! In this blog we shall explore fundamentals of AWS Glue(AG). What is Glue?Glue is service in which we can build ETL jobs both programmatically and visually. ETL stands for Extract Transform Load.
Any ETL jobs broadly has three phases. Firstly, extract the raw data. Secondly, apply some mathematical transformation. Thirdly and last phase, load the transformed data into a target location.
You might be wondering by this blog is important at first place! because there are many other blogs related to Glue. The reason is, in this website I shall publish multiple Glue blogs as Glue has quite a number of components to cover. These components are tightly coupled with each other. Hence, the name Glue!
You can find the youtube video of this article here.
Core Components of Glue:
- Crawlers: Its a program managed by Glue service. At high level, it extracts the meta data from a given source. Crawler invokes the Data Classifier.
- Data Classifier: Classifier has broadly has two jobs.Firstly, It reads the data format which help classifier to generate schema. Secondly, it return a certainty number, range from 1 to 0. When the classifier correctly classifies the data, it returns 1. Similarly, when it does not, it returns 0. In simple terms, if we do not include data classifier, crawler can’t detect the column names.
- Database and Table: After the crawler has extracted the metadata, it creates a table. Always remember these table does not hold the data. Data always stays in the original place. Therefore, AWS says its a Data Catalog. These tables are access from AWS Athena. Click here to know more about it.
- Data Catalog(DC) : The analogy that can be drawn is, its a booklet/magazine where we can observe the underlying construction at very high level. DC is catalog where metadata from different sources are present.
- Data Stores: When a crawler goes into a location to create metadata, table schema, that is called data stores.
- Data Sources: It is used when we are developing ETL jobs using notebook or visual console, we need to point to some specific location.
The Data flow Diagram of AWS GLUE:
The office data flow diagram of AWS GLUE is shown below :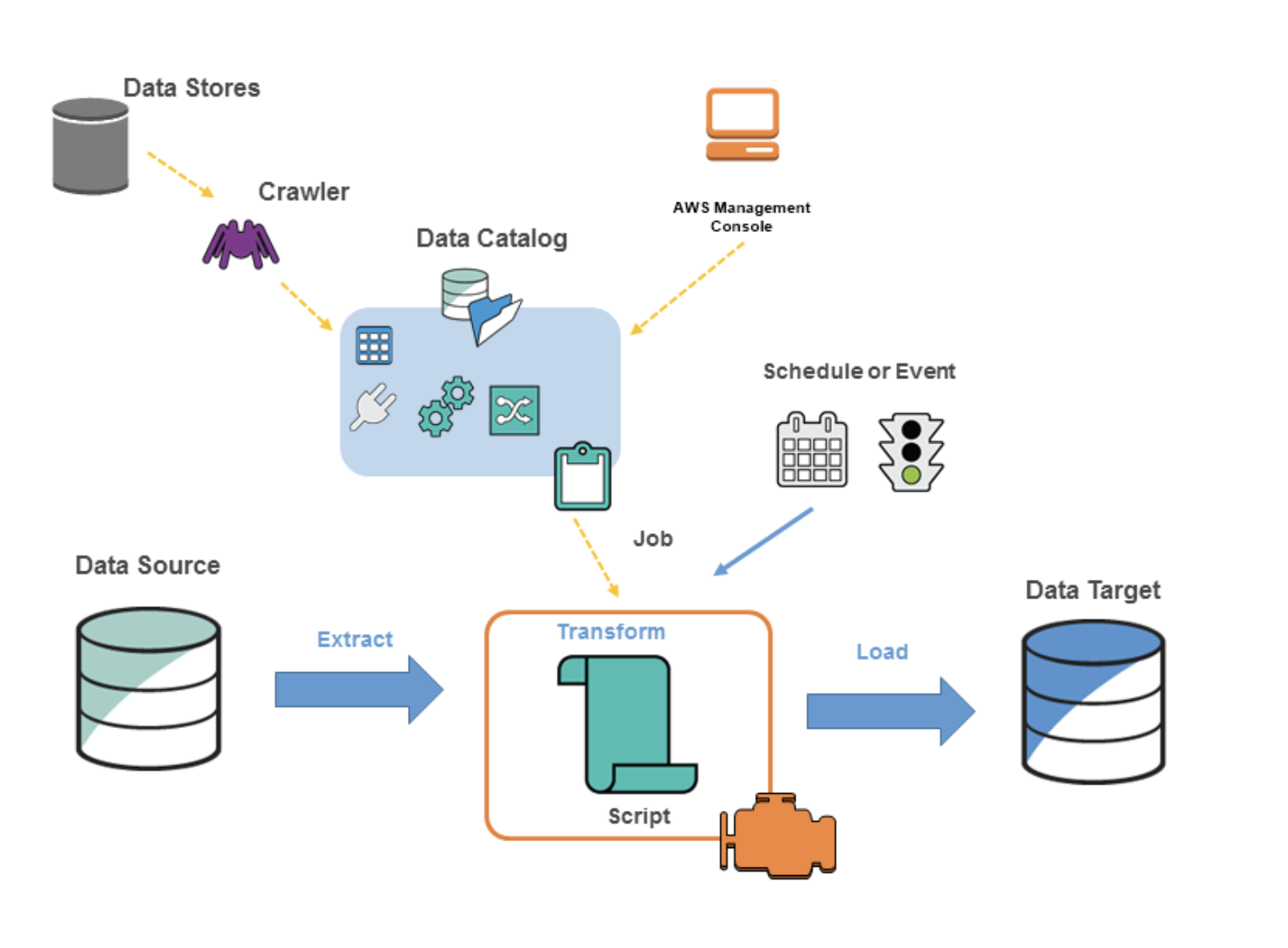
According to my experience, for beginner level we just need to understand that crawler will create a pseudo database and table.These table are mapped with the original data source. Based on those tables we have to create ETL jobs! Therefore, for a beginner level its advised not to go into the minute details of the image!
Now based on the discussion which we had so far, lets move to ETL!
Extract: This is the first step, here we are transferring the data from the source to a specially designed dynamic data-frame of aws glue! You can think of it as a pandas data-frame with some enhance features like distributed computing.
Transform: Any changes that we want to make may be on the column name or on the data itself are done in this phase only. Some set of operations that we can cover are column rename, dropping columns, deriving new columns from the existing columns. Hence, the name transformation.
Load: Once we are done with the tranformaton, we need to store it somewhere. With respect to AWS GLUE, we can move the transformed data into another folder of S3 bucket or we can also move the data to another place, that may be a database!
How ETL is done in AWS GLUE:
ETL inside Glue can be done either using Notebook,kind of a jupyter notebook or using a visual editor. In Visual editor, there are large number of transformation options, we can drag and drop nodes. We need to change the setting of the those nodes in order to work perfectly. On the other hand, when we use notebook, we have to manually write the code, mostly in pyspark. The only advantage is that we have more granular control over it. While using notebook, you will find lot a python operations that are going on.
In our upcoming blogs and videos, we shall dive deep into all of these topics.
Conclusion of AWS Glue:
AWS Glue is a compulsory skill that is required to become a data engineer. As it has a lot of operations that are in-build with it! Let me know if I have missed something to be included in this blog! Stay tuned, this website, its is just a overview of Glue. There are lot of things that are need to be covered. I shall publish those soon!