
Introduction Of NLP:
NLP is an acronym of Natural language processing. As we know the training in the AI model is one of the crucial parts of model building. And to train a model we need data. Therefore, data can we see as a fuel for all AI bases model. Broadly data is divided into two categories structured data and unstructured data. Structured data follow a proper format. In contrast, unstructured data is a form of information that is stored purely in the text form without any proper format.
The majority of the data that is generated is in textual form. Data that is generated from textual conversations like tweets, Facebook posts, mail threads, blogs, and chats are all examples of unstructured data. Even though we have a very high amount of unstructured data, extracting useful information is a big challenge. One of the reasons is when we chat or mail, we do not follow any predefined rules. Hence, data processing is the most time-consuming task in language processing.
In this article, we shall discuss the basics of NLP and some of its libraries. So at the end of the article, we shall be capable enough for basics operations on language processing.
What is NLTK?
Natural Language Toolkit(NLTK) is an open-source community-driven project. It is a platform build to work with human language. NLTK lays the foundation for a high level of language processing tasks.
How to install NLTK:
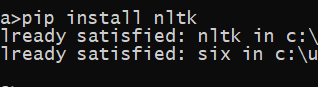

What is Spacy?:
It is an advanced natural language processing library which is also open-source, written in Python and Cython. Spacy is specially designed for high-level industry use. Therefore spacy can process large volumes of text. It also has the support of deep learning. There GPU specific spacy library.
How to install Spacy:
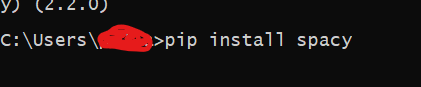
Installing only spacy won’t work. We need a language library for our operations. Picture below shows how to install an English library for spacy.

Install GPU based spacy:
Note: Before installing GPU based spacy, make sure cupy is installed. In the picture below, cuda[102], is the Cuda version.
The picture below shows how to install cupy.

Once cupy is installed, we can install spacy. The picture below shows the same.

Once spacy for GPU is installed. We need to explicitly call spacy.prefer_gpu() or spacy.require_gpu() in our code. This function call says the Python interpreter to use GPU for spacy algorithms.
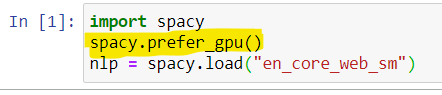
Text Processing:
Text processing is the process of extracting information from text data. The outcome of text processing results in structured text data. During the course of text processing, we follow certain rules. In other words, we can automate text processing using any high-level language like python. As raw text contains a lot of slags, it cannot be directly fed into NLP models. Therefore, cleaning of text, making it ready for NLP models becomes very vital.
In general, text processing is divided into three steps, ie noise removal, lexicon normalization, object standardization. In the upcoming section, we shall explore these topics one by one.

Noise Removal:
Whenever we talk, chat, send emails, we used lots of words that are necessary for the grammatical point of view. Similarly, there are also words that are used to wish someone. There can be URLs in a text document. We also use fillers like “hmm”, in chats we use “LOL”. These are the examples that make sense from the language point of view. However, these words become noise when it comes to NLP. NLP emphasizes those words which make that sentence more meaningful. Therefore these words are removed in text processing.
One way to remove noise can be, we shall put all possible noise words in a list. In the next step, we shall scan the text and drop those words that are present in the text. The picture below demonstrates the same. This is a python program that filters out the words which are not present in the list.
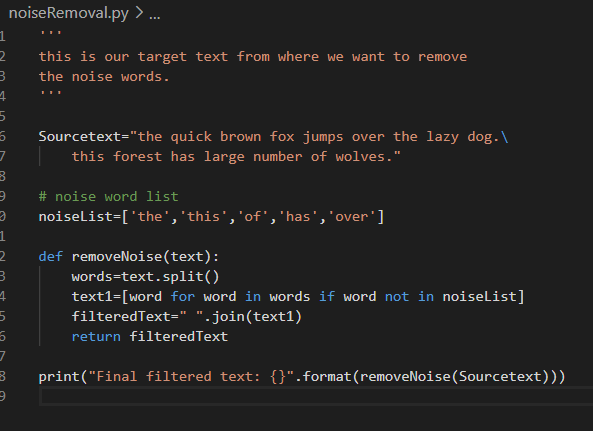
The picture below is the output of the above code.
![]()
Word Normalisation:
Tokenization is a process of converting sentences or paragraphs into individual words. Generally, tokenization is an easy process where individual words are pickup that is separated by space. However, words like “can’t”, “haven’t” are combined words. Moreover, it has completely opposite meanings. WordPunctTokenizer and TreebankWordTokenizer are the most widely used methods under the NLTK library for word tokenization. RegexTokenizer can split string bases on a regular expression. Most of the tokenization methods are rule-based.
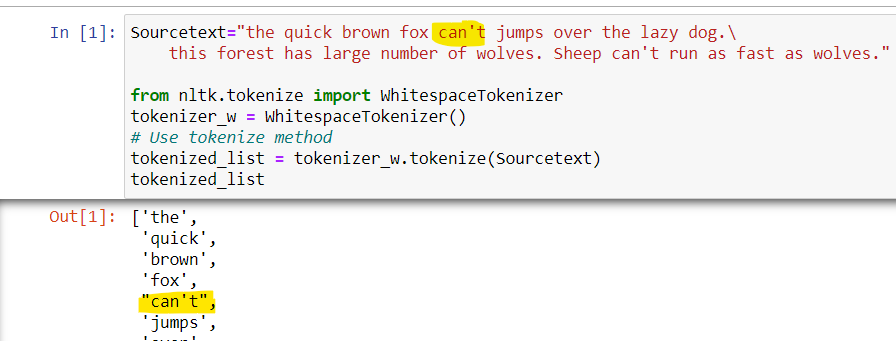
The picture below is the example of the word whitespace tokenizer. The working logic is simple, we shall pass the text to this function and of outcome and it returns individual words. If we look carefully, whitespace tokenization cannot separate “can’t” into “can not”.
Tokenization using spacy:
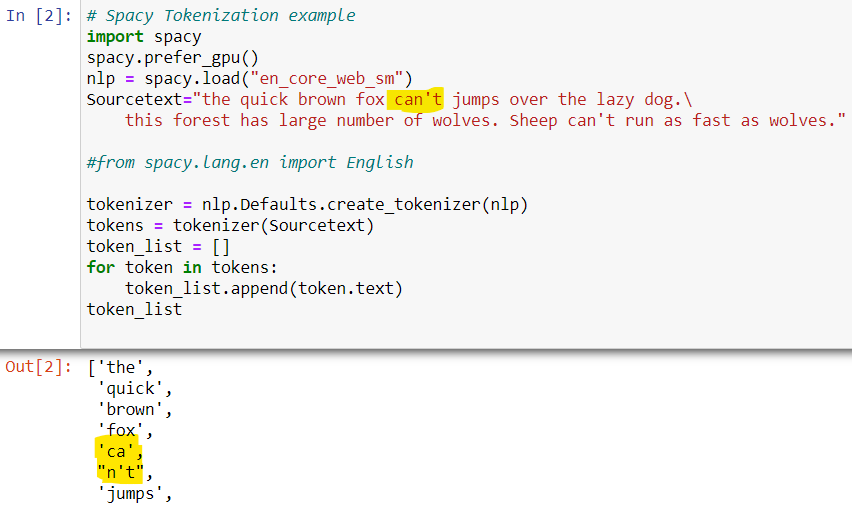
The picture below is an example of tokenization using spacy.
Lexical Normalization:
Lexical normalization is the task of converting various forms of a word into its original form. For example, multiplying, multiplied, is converted into multiple. Under lexical normalization, there are two important steps, that are stemming, lemmatization. Both these methods try to reach to root word but with a different approach.
Stemming: it is a simple method. In stemming, we simply chop the extra letters at the rear end of the word. For example, “running” becomes “run”. The advantage of stemming is, it’s fast. On the other hand, the disadvantage of stemming is it is less accurate and something simply chopping of letters does not return real dictionary words.
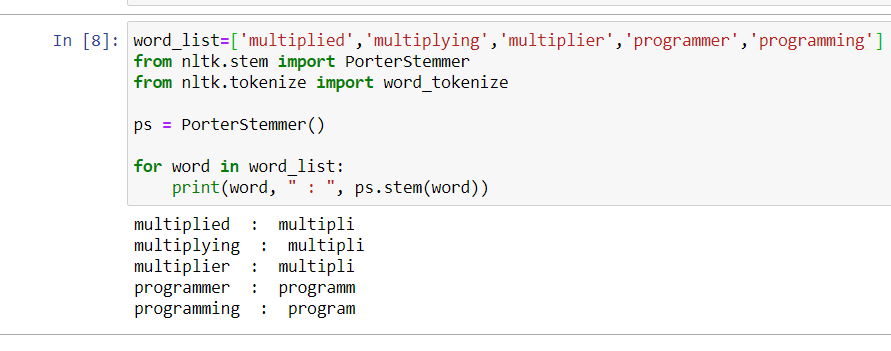
The picture below shows stemming using the NLTK library.
The word “multiplied” did not reach its core word “multiple”. On the other hand, the “programmer” reached its core word “program”. This is one of the disadvantages that we discussed above.
Lemmatization: It is a process of reaching to the lemma of a word. When we try to reach to the core word, lemma algorithm processes the word step by step. The final result is a core word that has a definite language meaning. As it is an algorithm, scholars around the globe keeping developing faster and more accurate methods to the reach final word.
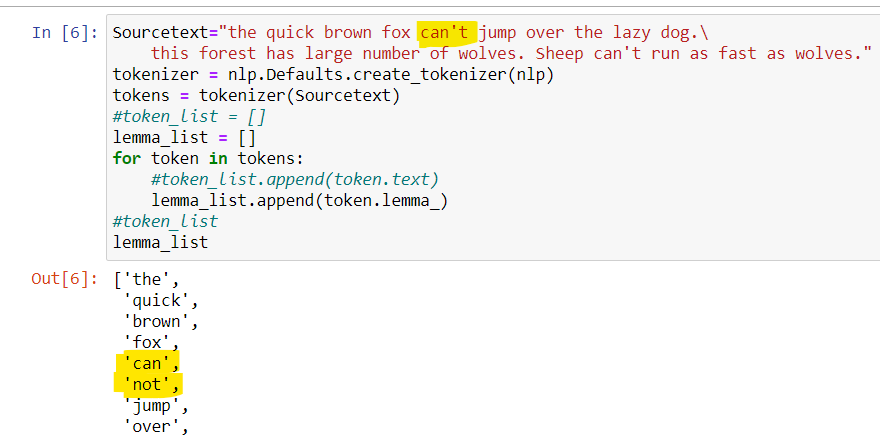
The picture below shows, the word “can’t” is successfully converted to “can not”, which was not possible using the NLTK library.
Stop-Words removal:
These are some of the most common words that we generally use at the time of framing sentences. There is no definite list of stop words in any language. Stop-words are used to make a sentence grammatically correct when we write or speak. However, for natural language processing, Stop-words doesn’t make sense. These words do not add up any significant meaning to a sentence. Few examples of stop-words are “this”,” is”,” at”,” which”, “on”, “that”.
Removal of stop-words using hard code:
In this method, we put all the probable stop-words in a list that we want to exclude from the text. However, Spacy already has a stop-word list which can be used when we import it.
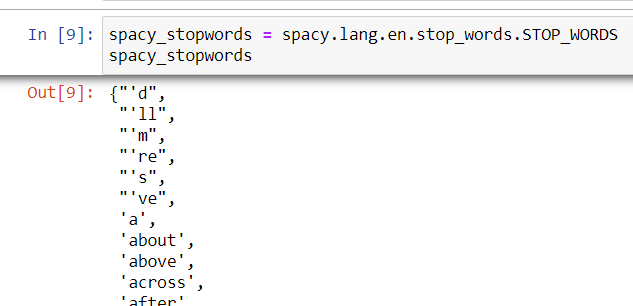
The picture below shows how to remove stop-words using Spcay’s in build library.
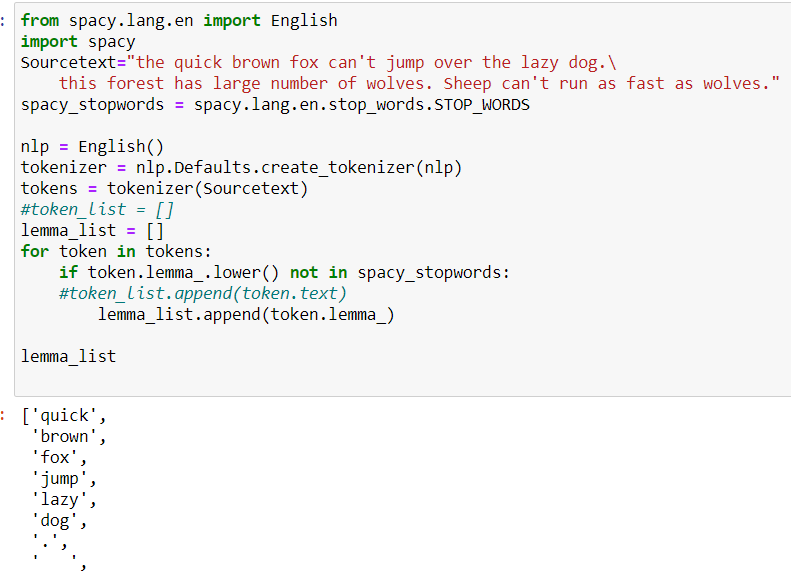
From here onwards, we shall convert the filtered text into features. In our next article, we shall discuss the methods which do the same.